データベース101: 初心者のためのデータ整合性 - DEV コミュニティ
データベースの勉強をもう一度楽しくしよう!!!
目次
TL:DR
この記事では、僕がデータベースの勉強中について学んだことで、今までデータベースの話題にワクワクしてきた点を共有します。
1. プロローグ
2022年の終わりに、データベースというテーマをもっとクリアにすることにしました。なぜなら、バックエンドデベロッパーとしては複雑なデータベースクエリを憎むことが楽だからです。その考えを踏まえて、僕はゼロから学び始めて、ちょっとした楽しみのためだけにこのあまり掘り下げられていない世界に挑戦しました。
2. MySQL以外にもたくさんの選択肢がある
僕は大学を卒業しておらず、学生時代にデータベースについて何も学びませんでした。なので、理論的なバックグラウンドはありません。そして、これまでの4年間、エンタープライズレベルでコーディングする際には、クリーンコードやSOLID、デザインパターンといった他のコード関連のことに完全に焦点を当てていました。そして、僕のデータベースに関する知識はSQL/MySQLとキャッシュ/Redisに関するものだけでした。
ググってみたりTwitterでコンテンツの推薦を尋ねてみたりした最初の5分で、"7 Database Paradigms"というビデオを見つけ、まるで目からウロコでした。Key-Valueとリレーショナルだけじゃないって、まじで?
以下はパラダイムとそれに該当する具体的な実装のリストです:
- キーバリュー: Redis
- ワイドカラム: Apache Cassandra、ScyllaDB、DynamoDB
- ドキュメント: MongoDB
- グラフ: Neo4J
- リレーショナル: MySQL、MariaDB、PostgreSQL
- 検索エンジン: ElasticSearch
- マルチモデル: FaunaDB、MongoDB、Redis など
3. SQLとNoSQL
新しい挑戦をしようとしているわけですから、僕の主な焦点は、今まで快適に感じていたすべてから離れて、以前に見たことがなかったものを調べることでした。それには、NodeJSの世界でよく聞いていたこの言葉、NoSQLも含まれます。
SQL (Structured Query Language)がMySQL、OracleDB、SQLServerに使用されていることは知っていましたが、「逆SQL」や「アンチSQL」といったものがなぜ存在するのかを理解しようとここでは試みていませんでした。手短に言うと、違いは以下の通りです:
// Structured
table: users
id: int
name: string
table: user_addresses
id: int
user_id: int references id in users
address: string
table: users
--------------------
| id | name |
| 1 | danielhe4rt |
--------------------
table: user_addresses
---------------------------------------------------------
| id | user_id | address |
| 1 | 1 | Flowers St. 123, São Paulo/SP - Brazil |
---------------------------------------------------------
フルスクリーンモードへのEnter
SQLは、テーブル、行、列によって駆動されます。
// database-prod.json
{
"users": [
"huid2d12bdh12b": {
"id": 1,
"name": "danielhe4rt",
"addresses": [
"jio32fsdyhis": {
"address": "Flowers St. 123, São Paulo/SP - Brazil"
}
]
}
]
}
フルスクリーンモードへのEnter
NoSQLは、文書、コレクション、フィールドによって駆動されます。
NoSQLには魅力的な特徴や調査するべき機能が山ほどあることが注目されます。キーバリュー、ドキュメント、ワイドカラムとして検討するオプションがあります。
僕が研究を掘り下げ続けて選んだのはワイドカラムデータベースでした。なぜなら、僕が見つけた2つのかっこいいトピックがあるからです。それはレプリケーションファクターと整合性レベルですが、その前にCAP定理について話をしなければなりません。
4. 賢く選ぶ
CAP定理はデータベースに基づいています。
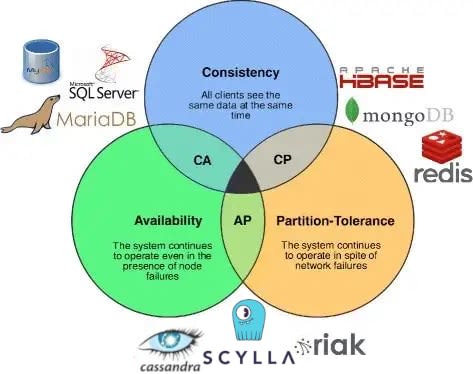
ある凄腕の人、エリック・ブリュワーは、分散データストアは、一貫性、可用性、分割耐性の3つの保証のうち2つしか提供できないと特定しました。まぁ、妥当な範囲であれば全部手に入れることは可能ですが、それは別の記事の話です。
じゃあこれらの項目って具体的には何?なんでこれに注意すべきなの?定理って数学のつまらないものじゃないの?違うんだよ、だからついてきてください!話しを続けると、これらの柱を理解する必要があります:
- 可用性(Availability):異なるノードにデータがあって、そのうちのいくつかが失敗してもデータは利用可能であること。
- 一貫性(Consistency):あるデータを更新しますが、レプリケーション操作が他のデータセンターで完了していないため、最新の書き込みが保証されないが、整合性レベルを使用して設定可能である。
- 分割耐性(Partition Tolerance):レプリカ/ノード間の通信に障害がある場合、操作は続行できるか?
この時点で、理解して続けるためのたくさんの概念がありますが、今からひとつの最終ステップと、この記事を書きたかった理由を見ていきましょう:ワイドカラムデータベースパラダイム!
5. 最もクールなデータベースパラダイム 😎
そうです、僕の意見でコッォイデータベースパラダイムはワイドカラムデータベースです。それでは理由を4つのトピックで説明します。
- パラダイム
- このパラダイムをベースに構築されたデータベース
- レプリケーションファクター
- 一貫性レベル
5.1 パラダイム
SQL言語で期待されるような行を考えるのではなく、カラムを考えながらモデリングすることを想像してみてください。これらのカラムはコレクションをベースにしているので柔軟性がありますが、クエリを実行するためにスキーマが必要です。
クエリに関して言えば、このパラダイムはNoSQLではないのでは?実はそうではないんです。Apache CassandraというデータベースがCassandra Query LanguageまたはCQLを導入しています。つまりクエリに関連するものがあるわけですね?
SQLではジョインがサポートされていますが、CQLではサポートされていません。クエリの書き方は、どちらのクエリ言語も似ています。
5.2 CassandraとScyllaDB
ワイドカラムを使用した最も有名なデータベースはまだCassandraですが、この価値あるCassandraの競合相手をまだ知らない多くの開発者によって選ばれています:ScyllaDBです。
何が違うの?同じパラダイムを使っているのだから、ほぼ同じでなくちゃいけない...よね?
全然違います。Apache CassandraはJavaを使って構築されたオープンソースツールで、ScyllaDBはこのデータベースパラダイムの読み書き操作を新次元にまで向上させる必要から生まれました。
ScyllaDBはC++で書かれており、低レベルに近いことから、2倍から8倍のパフォーマンス向上が得られます。この流れを追っていくと、よりパフォーマンスが高いため、維持コストが安くなるはずです。また、ScyllaDBは同じドライバーを使用しているので、CassandraからScyllaへの移行に多くの問題はありません。
それではかっこいい機能に移りましょう :p
5.3 レプリケーションファクター (RF)
CassandraとScyllaDBがサポートする機能の1つに、レプリケーションファクターがあります。これは、行に書き込んで、与えられたデータを利用可能な次のすべてのノードに複製するオプションを許可するフラグです。
RFを3に設定する場合、任意のデータを格納すると、そのデータは次の3つのノードに複製され、主要ノードがデータを失ってもデータがあることが保証されます。SimpleStrategyフラグはローカルクラスターでの複製を示し、NetworkTopologyStrategyフラグは複数のデータセンターでの複製を示します。

5.4 一貫性レベル
これで書き込み
こちらの記事はdev.toの良い記事を日本人向けに翻訳しています。
https://dev.to/danielhe4rt/database-101-why-so-interesting-1344








