ベクトル埋め込みって何?
埋め込みは、入力データの意味を数値化した機械学習の表現です。テキスト、画像、オーディオのような複雑で多次元のデータの意味をベクトルに変換します。これにより、アルゴリズムがデータをより効率的に処理し分析できるようになります。
ベクトル埋め込みを使う理由は?
自分のソーシャルメディアのフィードをスクロールしていて、内容が自分好みだなって感じたことはありませんか?自分が気になるニュースや、好きなテックスタックの完璧なチュートリアル、吹き出してしまうようなミームなどが続きます。
または、YouTubeが知らないクリエイターのおすすめのビデオを推薦してきて、それがすごく気に入ることがありませんか? あなたが理想のコンテンツラインアップについてYouTubeに何か伝えたわけでもないのに。
これが埋め込みのマジックです。
これは、ディープラーニングモデルがオンラインでのあなたの相互作用のデータを分析する結果です。いいねやシェア、コメント、検索、長く見ているコンテンツ、スキップしたコンテンツなどから算出されます。そしてアルゴリズムに、あなたが気に入りそうな未来のコンテンツを予測することも可能にします。
同じ埋め込みは、検索、広告、その他の機能に再利用でき、高度にカスタマイズされたユーザー体験を提供します。
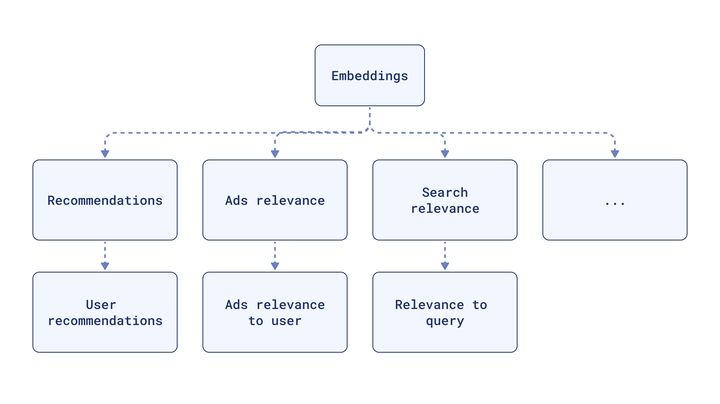
これが、多次元データをより扱いやすくする方法です。ストレージの要件を減らし、計算効率を向上させ、大量の非構造化データを理解可能にします。
埋め込みがどのように機能するのか?
自然言語の微妙な差異や、大規模な画像、音声、またはユーザー相互作用データセットに隠された意味を表に収めるのは難しいです。伝統的なリレーショナルデータベースは現在使われているほとんどのデータタイプを効率的に検索できず、この情報の取得が非常に限定的です。
埋め込み空間では、同義語が似た状況に現れることが多いため、似た埋め込みになります。この空間は、「きれい」と「魅力的」が同じチームでプレイしていることを、明示的に言われなくても理解するほど賢いです。
それがマジックです。
ベクトル埋め込みの核心は意味論です。「単語は、それが使われる環境によって知られる」という考えを大規模に適用します。

この能力は、検索システム、推薦エンジン、検索を拡張した生成(RAG)や、コンテンツの深い理解から恩恵を得るアプリケーションの作成に不可欠です。
埋め込みはニューラルネットワークを通じて作成されます。それらは複雑な関係や意味論を密なベクトルにキャプチャし、機械学習およびデータ処理アプリケーションにより適しています。それからこれらのベクトルを適切な高次元空間に投影できます。具体的には、ベクトルデータベースです。
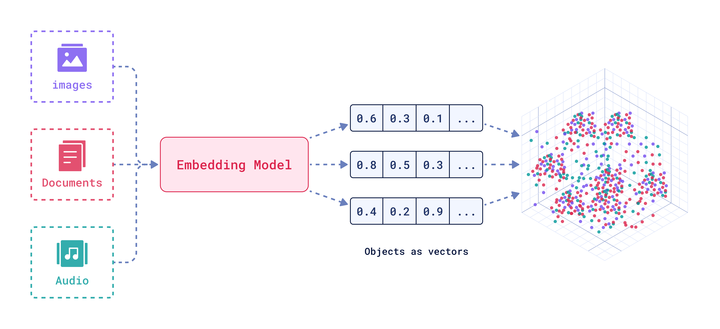
データポイントの意味は、ベクトル空間上の位置によって暗黙的に定義されます。ベクトルが保存された後、私たちはそれらの空間的性質を使用して最近傍探索を行い、この空間でどれだけ近いかに基づいて意味的に類似したアイテムを取得できます。
ベクトル表現の品質がパフォーマンスを推進します。あなたのユースケースに最適な埋め込みモデルは異なります。
ベクトル埋め込みの作成
埋め込みは、人間の言語の複雑さをコンピュータが理解できる形式に翻訳します。ニューラルネットワークを使用して、入力データに数値を割り当て、類似データが類似の値を持つようにします。
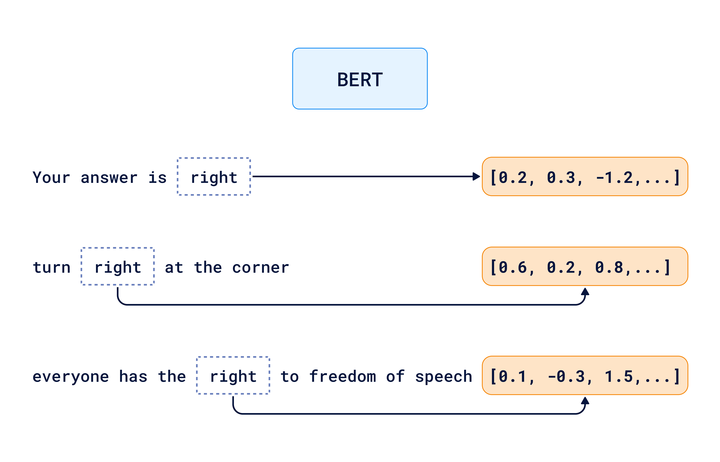
例えば、「right」という単語をコンピュータに理解させたい場合、1.3のような数字を割り当てることができます。つまりコンピュータが1.3を見たら、「right」という単語を見ているのです。
今度は「right」という単語の文脈をコンピュータに理解させたいとしましょう。[1.3, 0.8]のような二次元ベクトルを使って「right」を表すことができます。最初の数字1.3は引き続き単語「right」を識別し、二番目の数字0.8が文脈を指定します。
もっと多くの次元を導入して、より細かいニュアンスを捉えることができます。例えば、三次元目は単語のフォーマリティを表し、四次元目は感情的な語感(ポジティブ、ニュートラル、ネガティブ)を示すこともできます。
この概念の進化が、Word2VecやGloVeのような埋め込みモデルの開発に繋がりました。これらは、単語が現れる文脈を理解することを学び、それぞれの単語に対して遥かに複雑な属性を持つ高次元ベクトルを生成します。
しかし、これらのモデルにはまだ限界があります。それらはテキスト全体での使用に基づいて1つのベクトルを生成します。これは、「right」という単語の全てのニュアンスが1つのベクトル表現に混ざり合ってしまうことを意味します。これだけの情報では、コンピュータが文脈を完全に理解するには十分ではありません。
では、異なる文脈で言語の細かいニュアンスをコンピュータに理解させるには、どうすれば良いのでしょうか? つまり、以下の違いをどう区別するのでしょうか?
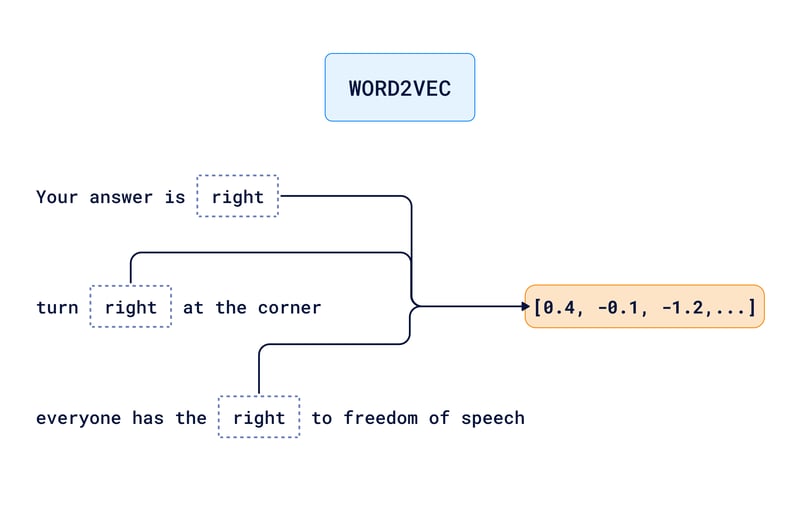
- 「あなたの答えは正しい(right)」
- 「角を右(right)に曲がって」
- 「すべての人は表現の自由(right)を持っている」
これらの文では、異なる意味で「right」という単語が使われています。
BERTやGPTのようなより進んだモデルは、トランスフォーマーアーキテクチャに基づいたディープラーニングモデルを使用し、コンピュータに単語の完全な文脈を考慮させます。これらのモデルは、単語の具体的な使用をその環境で理解し、それに応じて異なる埋め込みを作成します。
しかし、この理解と解釈のプロセスは現実の中でどのように機能するのでしょうか? たとえば「バイオフィリックデザイン」という用語を考えてみましょう。その埋め込みを生成するために、トランスフォーマーアーキテクチャは次のような文脈を使うことができます。
- 「バイオフィリックデザインは、自然の要素を建築計画に取り入れることです。」
- 「バイオフィリックデザイン要素を取り入れたオフィスは、従業員の幸福度が高いと報告しています。」
- 「...植物生活、自然の光、水の特徴はバイオフィリックデザインの重要な側面です。」
そしてそれを既知の建築およびデザインの原則と比較します。
- 「持続可能なデザインは環境との調和を優先します。」
- 「人間工学に基づいた空間は、使用者の快適さと健康を向上させます。」
モデルは、「バイオフィリックデザイン」についてのベクトル埋め込みを生成し、それは自然な要素を人工環境に統合する概念を包括します。この統合と、健康、幸福、環境持続性へのポジティブな影響との間の相関を強調する属性で拡張されます。
埋め込みAPIとの統合
あなたのユースケースに最適な埋め込みモデルを選択することは、アプリケーションのパフォーマンスにとって極めて重要です。Qdrantは、Cohere、Gemini、Jina Embeddings、OpenAI、Aleph Alpha、Fastembed、AWS Bedrockを含む埋め込みAPIの最高の選択肢とシームレスに統合することで、このプロセスを簡単にします。
NLPおよび迅速なプロトタイピングが必要な場合(言語変換、質問応答、テキスト生成を含む)、OpenAIは優れた選択肢です。Geminiは画像検索、複製検出、クラスタリングタスクに最適です。
下記の例で使用するFastembedは効率と速
こちらの記事はdev.toの良い記事を日本人向けに翻訳しています。
https://dev.to/qdrant/what-are-vector-embeddings-24pd








